Mybatis回顾
代码自动生成器 generator
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE generatorConfiguration PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN" "http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd" >
<generatorConfiguration>
<!-- 配置文件 -->
<properties resource="generator.properties"></properties>
<!-- 配置数据库的context -->
<context id="MysqlContext" targetRuntime="MyBatis3" defaultModelType="flat">
<!-- 设置文件编码 -->
<property name="javaFileEncoding" value="UTF-8"/>
<!-- 由于beginningDelimiter和endingDelimiter的默认值为双引号("),在Mysql中不能这么写,所以还要将这两个默认值改为` -->
<property name="beginningDelimiter" value="`"/>
<property name="endingDelimiter" value="`"/>
<!-- 为生成的Java模型创建一个toString方法 -->
<plugin type="org.mybatis.generator.plugins.ToStringPlugin"></plugin>
<!-- 为生成的Java模型类添加序列化接口,并生成serialVersionUID字段 -->
<plugin type="com.tudou.common.plugin.SerializablePlugin">
<property name="suppressJavaInterface" value="false"/>
</plugin>
<!-- 生成在XML中的<cache>元素 -->
<plugin type="org.mybatis.generator.plugins.CachePlugin">
<!-- 使用ehcache -->
<property name="cache_type" value="org.mybatis.caches.ehcache.LoggingEhcache" />
<!-- 内置cache配置 -->
<!--
<property name="cache_eviction" value="LRU" />
<property name="cache_flushInterval" value="60000" />
<property name="cache_readOnly" value="true" />
<property name="cache_size" value="1024" />
-->
</plugin>
<!-- Java模型生成equals和hashcode方法 -->
<plugin type="org.mybatis.generator.plugins.EqualsHashCodePlugin"></plugin>
<!-- 生成的代码去掉注释 -->
<commentGenerator type="com.tudou.common.plugin.CommentGenerator">
<property name="suppressAllComments" value="true" />
<property name="suppressDate" value="true"/>
</commentGenerator>
<!-- 数据库连接 -->
<jdbcConnection driverClass="${generator.jdbc.driver}"
connectionURL="${generator.jdbc.url}"
userId="${generator.jdbc.username}"
password="123456" />
<!-- model生成 -->
<javaModelGenerator targetPackage="com.tudou.dao.model" targetProject="tudou/tudou-dao/src/main/java" />
<!-- MapperXML生成 -->
<sqlMapGenerator targetPackage="com.tudou.dao.mapper" targetProject="tudou/tudou-service/src/main/java" />
<!-- Mapper接口生成 -->
<javaClientGenerator targetPackage="com.tudou.dao.mapper" targetProject="tudou/tudou-dao/src/main/java" type="XMLMAPPER" />
<!-- 需要映射的表 -->
<table tableName="view_class_data" domainObjectName="ViewClassData">
<!-- 同表字段生成 -->
<property name="useActualColumnNames" value="true"/>
</table>
</context>
</generatorConfiguration>
关联查询,嵌套查询
public class Users {
private int id;
private String userName;
private int userAge;
private String userAddress;
}
public class Article {
private int id;
private Users user;//外键
private String title;
private String content;
}
public class Blog {
private int id;
private String title;
private List<Article> articles;
}
关联查询
<resultMap type="User" id="userResultMap">
<!-- 属性名和数据库列名映射 -->
<id property="id" column="user_id" />
<result property="userName" column="user_userName" />
<result property="userAge" column="user_userAge" />
<result property="userAddress" column="user_userAddress" />
</resultMap>
<!-- User join Article进行联合查询 (一对一)-->
<resultMap id="articleResultMap" type="Article">
<id property="id" column="article_id" />
<result property="title" column="article_title" />
<result property="content" column="article_content" />
<!-- 将article的user属性映射到userResultMap -->
<association property="user" javaType="User" resultMap="userResultMap"/>
</resultMap>
<!-- 使用别名来映射匹配 -->
<select id="getUserArticles" parameterType="int" resultMap="articleResultMap">
select user.id user_id,user.userName user_userName,user.userAddress user_userAddress,
article.id article_id,article.title article_title,article.content article_content
from users user,article
where user.id=article.userid and user.id=#{id}
</select>
嵌套查询
<resultMap id="blogResultMap" type="Blog">
<id property="id" column="blog_id" />
<result property="title" column="blog_title" />
<!-- 将article list属性映射到collection -->
<collection property="articles" ofType="Article" resultMap="articleResultMap"/>
</resultMap>
<!-- select语句 -->
<select id="getBlogByID" parameterType="int" resultMap="blogResultMap">
select user.id user_id,user.userName user_userName,user.userAddress user_userAddress,
article.id article_id,article.title article_title,article.content article_content,
blog.id blog_id, blog.title blog_title
from users user,article,blog
where user.id=article.userid and blog.id=article.blogid and blog.id=#{id}
</select>
缓存使用场景和选择策略
MyBatis将数据缓存设计成两级结构,分为一级缓存、二级缓存,没有层级关系,只是命名而已。
一级缓存
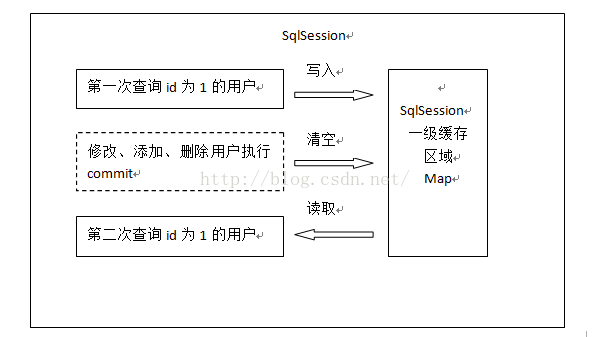
MyBatis在SqlSession对象中建立一个简单的缓存,将每次查询到的结果结果缓存起来,当下次查询的时候,如果判断先前有完全一样的查询,会直接从缓存中直接将结果取出,返回给用户。其内部就是通过一个简单的HashMap<k,v> 来实现的。
每当我们使用MyBatis开启一次和数据库的会话,MyBatis会创建出一个SqlSession对象表示一次数据库会话。一级缓存是Session会话级别的缓存,位于数据库会话的SqlSession对象之中,又被称之为本地缓存。一级缓存是MyBatis内部特性,用户不能配置。且默认情况下mybatis自动支持这种缓存,用户没有定制它的权利(除非通过开发插件对它进行修改)。 每个SqlSession中的缓存都是独立的。
-
如果SqlSession调用了close()方法,会释放掉一级缓存PerpetualCache对象,一级缓存将不可用;
-
如果SqlSession调用了clearCache(),会清空PerpetualCache对象中的数据,但是该对象仍可使用;
-
SqlSession中执行了任何一个update操作(update()、delete()、insert()) ,都会清空PerpetualCache对象的数据,但是该对象可以继续使用;
二级缓存
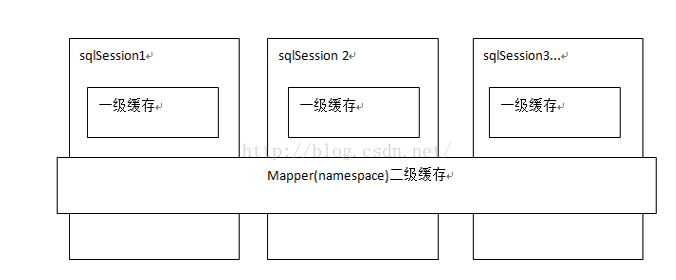
-
与一级缓存相比,二级缓存的范围更大。多个sqlSession可以共享一个UserMapper的二级缓存区域。其内部也是通过HashMap<k,v> 来实现的。
-
每个Mapper对象(如:Mapper.xml)都会有一个与之对应的二级缓存区域。
-
mybatis根据Mapper对象的namespace区分,如果两个mapper的namespace相同,即使是两个mapper,那么这两个mapper中执行sql查询到的数据也将存在相同的二级缓存区域中。可以认为在hashMap中存储时,是以namespace作为主键的。
-
如果两个mapper的namespace如果相同,任意一个mapper的写操作,都会清空整个namespace缓存。
mybaits的二级缓存是mapper范围级别,要想使某条Select查询支持二级缓存,你需要做以下几步开启:
设置 MyBatis支持二级缓存的总开关:全局配置变量参数 cacheEnabled="true"
<settings>
<!-- 对在此配置文件下的所有cache 进行全局性开/关设置 默认值为true -->
<setting name="cacheEnabled" value="true"/>
</settings>
该select语句所在的Mapper,配置了 或节点,并且有效
<!-- 在UserMapper.xml中开启二缓存,UserMapper.xml下的任意sql执行完成后,都会存储到它的缓存区域(HashMap) -->
<mapper namespace="twm.mybatisdemo.mapper.UserMapper">
<!-- 开启本mapper namespace下的二级缓存 -->
<cache></cache>
可以看到
Mybatis Cache参数设置:
-
flushInterval(刷新间隔)可以被设置为任意的正整数,而且它们代表一个合理的毫秒形式的时间段。默认情况是不设置,也就是没有刷新间隔,缓存仅仅调用语句时刷新。
-
size(引用数目)可以被设置为任意正整数,要记住你缓存的对象数目和你运行环境的可用内存资源数目。默认值是1024。
-
readOnly(只读)属性可以被设置为true或false。只读的缓存会给所有调用者返回缓存对象的相同实例。因此这些对象不能被修改。这提供了很重要的性能优势。可读写的缓存会返回缓存对象的拷贝(通过序列化)。这会慢一些,但是安全,因此默认是false。
-
eviction(回收策略)。可用的回收策略有:
- LRU – 最近最少使用的:移除最长时间不被使用的对象。
- FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
- SOFT – 软引用:移除基于垃圾回收器状态和软引用规则的对象。
- WEAK – 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。 默认的是:LRU
如下例子:
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
这个更高级的配置创建了一个 FIFO 缓存,并每隔 60 秒刷新,存数结果对象或列表的 512 个引用,而且返回的对象被认为是只读的,因此在不同线程中的调用者之间修改它们会导致冲突。
需要用到缓存的select语句的参数 useCache=”true”
<select id="selectById" parameterType="int" resultType="User" useCache="true">
select * from user where id=#{id}
</select>
POJO类序列化
pojo类实现序列化接口是为了将缓存数据取出执行反序列化操作。因为二级缓存数据存储介质多种多样,不一定都是存在内存,有可能是硬盘或者远程服务器。
public class User implements Serializable{
private static final long serialVersionUID = 1L;
Integer id;
....
}
禁用二级缓存: 在statement中设置useCache=false可以禁用当前select语句的二级缓存,即每次查询都会发出sql去查询,默认情况是true,即该sql使用二级缓存。
<selectid="findOrderListResultMap" resultMap="ordersUserMap" useCache="false">
总结:针对每次查询都需要最新的数据sql,要设置成useCache=
对查询频率高,变化频率低的数据建议使用二级缓存。
对于访问多的查询请求且用户对查询结果实时性要求不高,此时可采用mybatis二级缓存技术降低数据库访问量,提高访问速度
业务场景比如:
-
耗时较高的统计分析sql.
-
电话账单查询sql等.
实现方法如下:通过设置刷新间隔时间,由mybatis每隔一段时间自动清空缓存,根据数据变化频率设置缓存刷新间隔flushInterval,比如设置为30分钟、60分钟、24小时等,根据需求而定。